# Tech Stack
本篇文章將會使用到以下的技術:
基本的 JavaScript、Node.js、Git、GitHub、npm、discord.js、openai 套件等等的基礎知識,
# 創建 Discord Bot
首先,我們需要創建一個 Discord Bot,進到 Discord 開發者介面 → Discord Developer Portal — My Applications 初始化機器人 Discord Developer Portal 來創建一個新的 Bot。
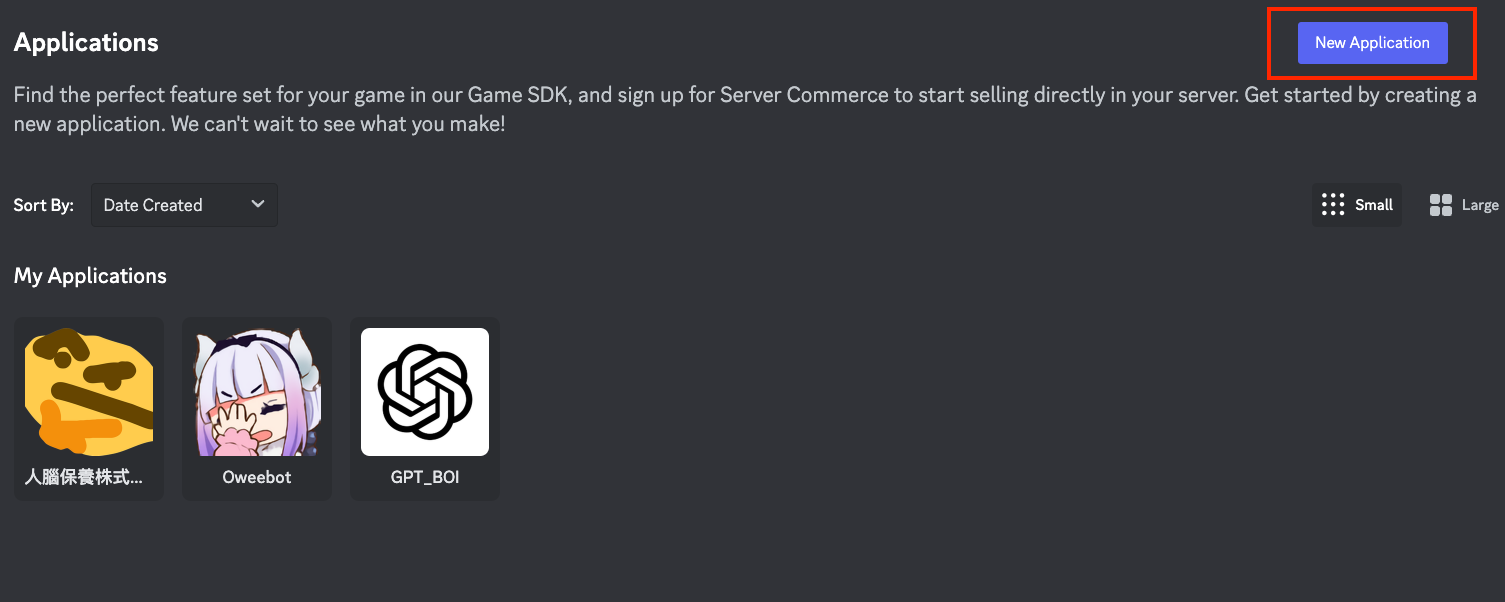
注意,此應用程式的名稱不是機器人的名稱,到時候這個應用程式名稱會變成 Discord 伺服器的權限名稱,所以請記得要取一個簡潔、易懂的名字。
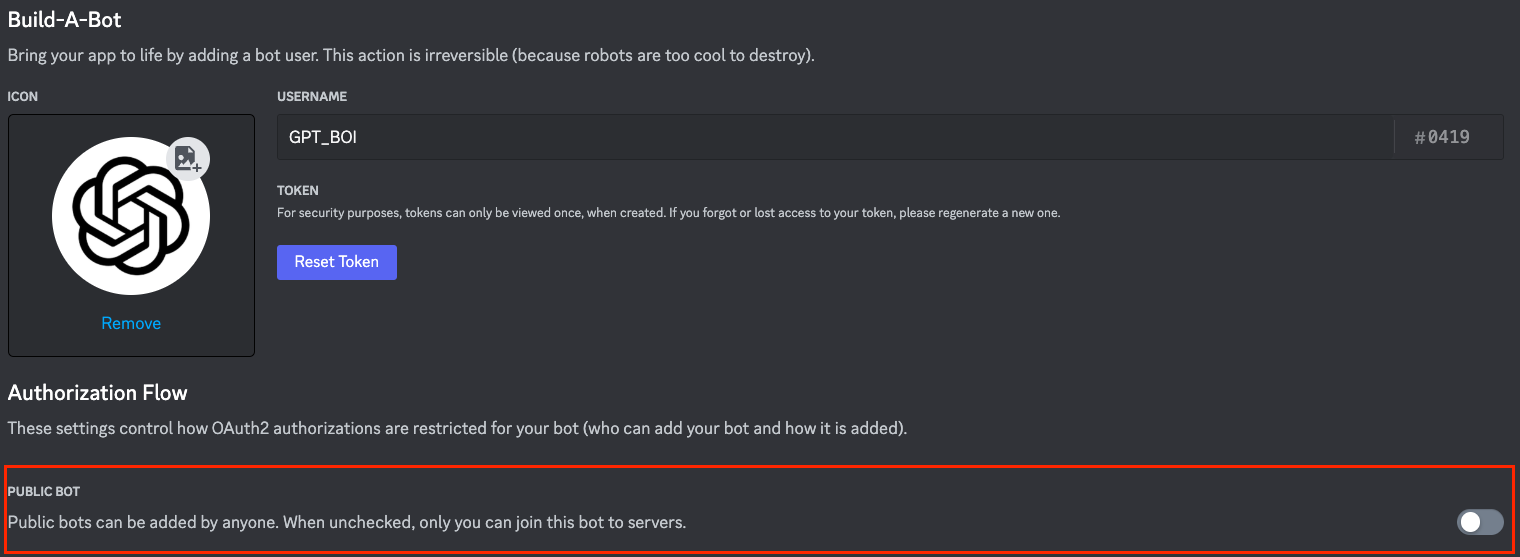
進到自己創建的應用程式內後,這邊我以「GPT_BOI」為例,點選左邊的「Bot」,並 disabled 「Public Bot」選項,因為我不希望自己的 GPT 機器人被其他人濫用,只讓自己指定的伺服器使用。
接下來到 OAuth2 頁面,勾選「bot」選項,並在 BOT PERMISSIONS 只先選擇 「 Send Messages 」,
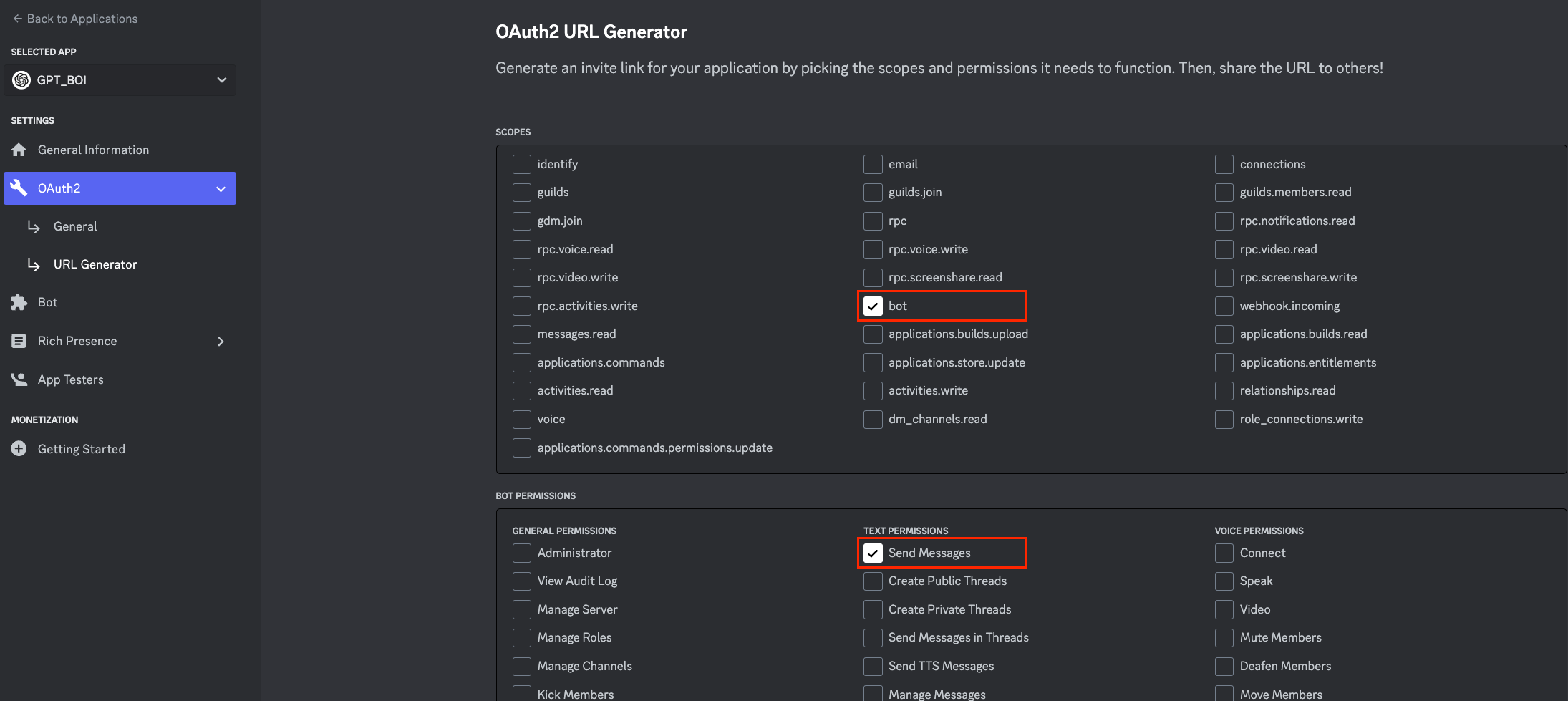
BOT PERMISSIONS 指的是機器人權限,由於我們不希望機器人被濫用去 PING 所有人或是刪除訊息等等,所以只需先勾選「 Send Messages 」即可。
直接到底部複製 GENERATE URL 的網址,並貼到自己的 Discord 伺服器,就能邀請機器人進入伺服器了。
# 建立開發環境並用 npm 初始化專案
首先建立一個資料夾,並進入資料夾內。
mkdir GPT_DISCORD_BOT
cd GPT_DISCORD_BOT接下來,初始化一個 npm 專案,這邊我們使用 npm init 來初始化專案。
當輸入 init 時,會出現一個 package.json 檔案,這個檔案是 npm 專案的設定檔,裡面會記錄專案的名稱、版本、作者、授權等等的資訊,這邊我們可以直接使用預設值,若不加 -y 參數,則會需要一步步輸入專案資訊。
npm init -y接下來安裝一些使用到的套件
- dotenv: 用來讀取 .env 檔案
- discord.js: 用來操作 Discord 的套件
- openai: 用來操作 OpenAI GPT 模型的套件
npm install dotenv discord.js openai# 建立 .env 檔案
先建立一個 .env 檔案用來存放 Discord Application 的 Token 以及 GPT API 的 Token,
一般會把 .env 檔案加入到 .gitignore 內,避免連同上傳到 GitHub。洩露自己的 Token。
TOKEN =
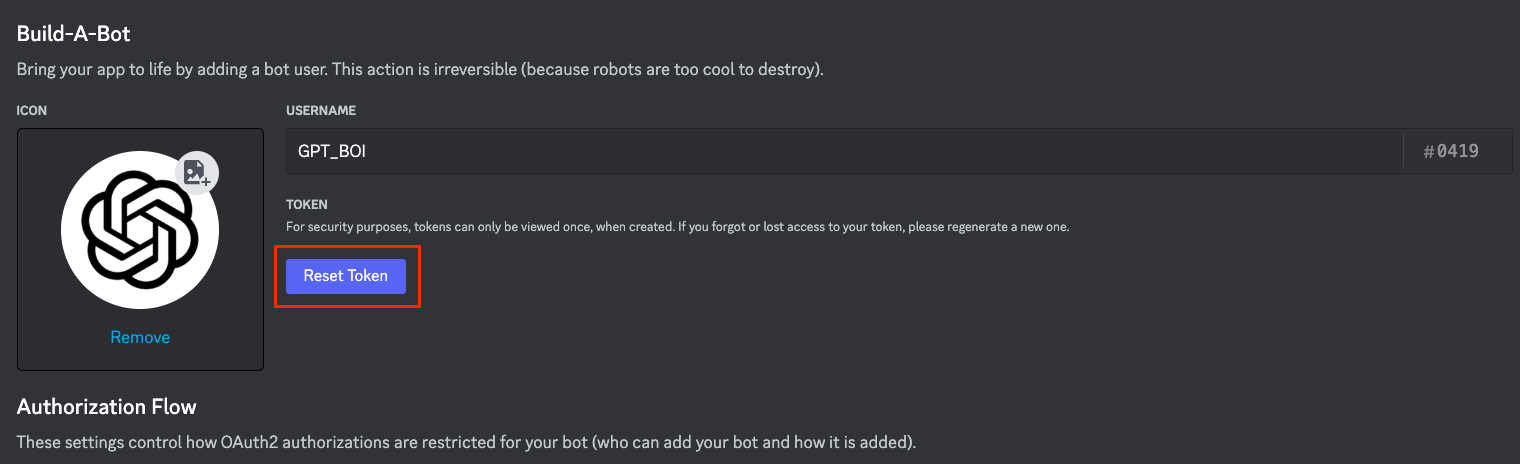
OPENAI_API_KEY =先到 Discord 開發者介面 → Discord Developer Portal — My Applications → GPT_BOI → Bot 頁面,點擊 Reset Token 來複製 Token 貼到 .env 檔案內。
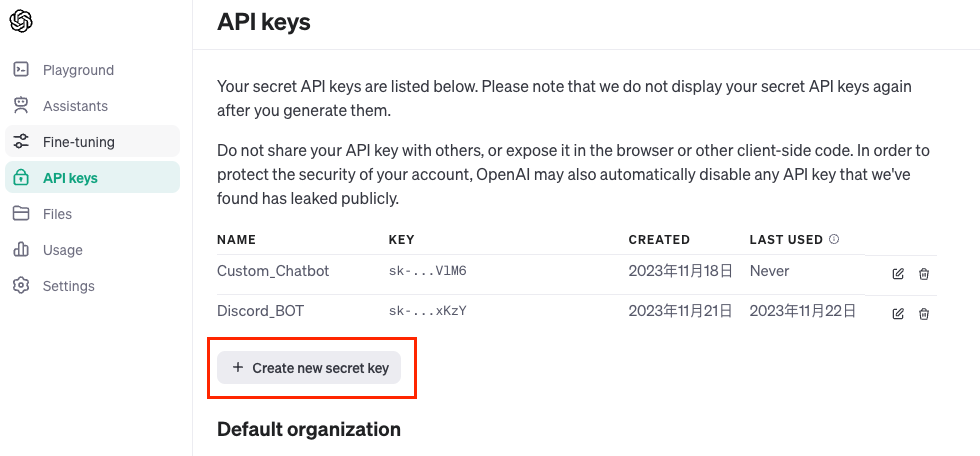
接下來換複製 OpenAI 的 GPT 的 TOKEN,登入帳號後點擊 API Keys -> Create New API Key 來創建一個新的 API Key,一樣複製到 .env 檔案內。
# 開始撰寫程式碼
首先,先建立一個 index.js 檔案,並引入相關套件。
node.js 引入套件的方法是使用 require()
require("dotenv/config");
const { Client } = require("discord.js");
const { OpenAI } = require("openai");# 建立並設計 Discord Client 的基本功能與邏輯
接下來,初始化一個 Discord Client,並設定好 intents,這邊我們需要用到 Guilds、GuildMembers、GuildMessages、MessageContent 四種 intents。
- Guilds: 用來訪問伺服器(Guild)相關的基本信息,例如伺服器的名稱、描述、圖示、角色和頻道列表等
- GuildMembers: 用來取得伺服器成員的用戶名、暱稱、加入時間、角色分配
- GuildMessages: 用於接收和處理伺服器頻道中的訊息,包括讀取、發送、編輯或刪除詗息的能力
- MessageContent: 使機器人能夠訪問訊息內容,包括文字、圖片、附件等
intents 就是決定我們的機器人要做什麼事情,而這邊會需要 "Guilds", "GuildMembers", "GuildMessages", "MessageContent" 這四個權限,所以就先把官方的程式碼修改成以下並貼入到 index.js 中
const client = new Client({
intents: ["Guilds", "GuildMembers", "GuildMessages", "MessageContent"],
});
client.on("ready", () => {
console.log(`GG人上線囉!`);
});
client.login(process.env.TOKEN);接下來我們可以先測試一下,是否能夠成功登入機器人,直接在終端機輸入 node index.js 來執行程式碼,若成功登入,則會在終端機顯示 GG人上線囉!。並且到 Discord 伺服器內,應能看到機器人上線。
然後我們可以再測試否能夠成功讀取到伺服器內的訊息,使用 messageCreate 事件來讀取訊息,看看在 Discord 輸入的訊息內容,是否有在終端機被顯示出來。
client.on("messageCreate", async (message) => {
console.log(message.content);
});接下來設置機器人 PREFIX,因為有可能並不是所有的訊息都是要讓機器人來處理,所以我們可以設置一個 PREFIX,若訊息含有 PREFIX 就忽略
並設置一個 CHANNEL_ID 陣列,讓機器人可在「多個」指定的頻道內回應訊息。
const IGNORE_PREFIX = "!"; // 讓機器人忽略以 ! 開頭的訊息
const CHANNEL_ID = ["1162717928697901116"]; // Discord 頻道 ID,可多個現在開始進行更進階的設定
- 確定此訊息是由使用者發出,而非機器人
- 檢查訊息如果是以 ! 開頭,則忽略不處理
- 檢查訊息是否在指定的頻道內,若不在指定的頻道內,則忽略不處理且同時檢查訊息是否有提及機器人,在「指定頻道內」的話不用提及機器人也能觸發讓機器人回應訊息。
client.on("messageCreate", async (message) => {
if (message.author.bot) return; // 如果訊息是由機器人發出,則忽略不處理
if (message.content.startsWith(IGNORE_PREFIX)) return; // 如果訊息是以 ! 開頭,也忽略不處理
if (!CHANNEL_ID.includes(message.channel.id) && !message.mentions.users.has(client.user.id)) return;
});確保能收到訊息並且也能依照需求及按照邏輯來處理、過濾訊息後,接下來就要來串接 OpenAI 的 GPT 模型了,讓機器人能夠回應我們了。
# Discord Client 常用 Event(事件)
- ready:當機器人啟動時觸發
- interactionCreate:當使用者呼叫機器人的指令時觸發
- messageCreate:當使用者發送訊息時觸發
# 開始調用 OpenAI API 模型來回覆訊息
為了能送 request 給 OpenAI 的模型,必須先初始化一個 OpenAI 的 Client,並設定好 apiKey 屬性,一樣將 apiKey 屬性設定為 .env 檔案中的 OPENAI_API_KEY。
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});寫完檢查機制後,接下來就要撰寫指定要使用哪個 OpenAI 的 GPT 模型來生成回覆了,OpenAI 提供了多種模型,這邊使用最便宜的 gpt-3.5-turbo-1106 模型。
role 屬性是用來指定訊息的角色,例如:
- assistant: 代表聊天模型本身,即人工智能助手。它負責產生回應和提供信息。
- system: 用於系統消息或指令,如初始設置或對話流程控制。
- user: 代表與聊天模型互動的人類用戶,通常是提問或發起對話的一方。
client.on("messageCreate", async (message) => {
if (message.author.bot) return; // 如果訊息是由機器人發出,則忽略不處理
if (message.content.startsWith(IGNORE_PREFIX)) return; // 如果訊息是以 ! 開頭,也忽略不處理
if (!CHANNEL_ID.includes(message.channel.id) && !message.mentions.users.has(client.user.id)) return;
const response = await openai.chat.completions.create({
model: "gpt-3.5-turbo-1106",
messages: [
// 回覆的訊息資料結構為一個陣列,裡面包含多個物件
{
// name: 'GG',
role: "system",
content: "我是一個友善的生成式預訓練模型",
},
{
// name: 'GG',
role: "user",
content: message.content, // 使用者輸入的訊息內容
},
],
});
message.reply(response.choices[0].message.content); // 將 OpenAI GPT 模型回傳的訊息內容回覆給使用者
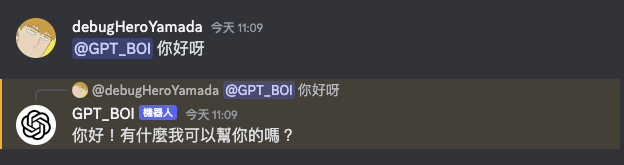
});此時一樣執行看看 node index.js,並且在 Discord 伺服器內輸入訊息,查看機器人是否能成功回覆。
# 撰寫例外錯誤處理程式
為了避免程式碼出現預期外的錯誤,然後沒有動靜,可以撰寫一個例外錯誤處理程式,當程式碼出現錯誤時,就會顯示錯誤訊息,並且不會讓程式碼停止執行。
client.on("messageCreate", async (message) => {
if (message.author.bot) return; // 如果訊息是由機器人發出,則忽略不處理
if (message.content.startsWith(IGNORE_PREFIX)) return; // 如果訊息是以 ! 開頭,也忽略不處理
if (!CHANNEL_ID.includes(message.channel.id) && !message.mentions.users.has(client.user.id)) return;
const response = await openai.chat.completions
.create({
model: "gpt-3.5-turbo-1106",
messages: [
// 回覆的訊息資料結構為一個陣列,裡面包含多個物件
{
// name: 'GG',
role: "system",
content: "我是一個友善的生成式預訓練模型",
},
{
// name: 'GG',
role: "user",
content: message.content, // 使用者輸入的訊息內容
},
],
})
.catch((error) => {
console.log("OpenAI 模型發生錯誤:( :\n", error);
});
message.reply(response.choices[0].message.content); // 將 OpenAI GPT 模型回傳的訊息內容回覆給使用者
});# 撰寫「機器人正在輸入...」程式碼
首先在 messageCreate 事件內,加入 await message.channel.sendTyping(); 來讓機器人顯示正在輸入中的狀態,接著使用 setInterval() 來定時發送正在輸入中的狀態,並且設定每 4 秒發送一次,直到 OpenAI 模型回傳訊息後,清除定時器。
因為在 Discord 中,「正在輸入...」的狀態不會持續很長時間,最新 API 文件顯示約 10 秒後就會消失。如果機器人需要花一些時間來處理或生成回覆,持續發送「正在輸入...」的信號可以讓用戶知道機器人還在活躍地處理他們的請求,而不是停止響應或出錯。
client.on("messageCreate", async (message) => {
...
await message.channel.sendTyping(); // 讓機器人顯示正在輸入中的狀態
const sendTypingInterval = setInterval(() => {
message.channel.sendTyping();
}, 5000);
const response = await openai.chat.completions.create({
...
});
clearInterval(sendTypingInterval); // 確定機器人已經回覆訊息後,清除定時器
});當然為了一樣要撰寫例外錯誤處理程式碼,當程式碼出現錯誤時,就會顯示錯誤訊息,並且不會讓程式碼停止執行。
client.on("messageCreate", async (message) => {
...
clearInterval(sendTypingInterval); // 確定機器人已經回覆訊息後,清除定時器
});
if (!response) {
return message.reply("我現在有點忙啦!,請稍後再試=="); // 如果沒有回覆,則回覆使用者
}到這邊,一個最基本的 GPT Discrod 機器人就完成了
# 優化機器人的腦袋
其實目前稍微用一下就能發現很多問題,例如:
- 偏笨 (畢竟是還在用便宜的 GPT-3.5 Turbo)
- 無法記住上下文,只能單一回覆
尤其第二點是最需要改進的,無法記住上下文的機器人基本等同於回到沒有 ChatGPT 的年代,毫無任何價值。
所以接下來可以在 GPT 回覆之前,先將使用者的訊息儲存起來,並且在下一次回覆時,將先前的訊息一併傳入 GPT 模型中,讓 GPT 模型能夠記住上下文。
第一個 push 至 conversation 陣列中的訊息就是 GPT 模型的初始 prompt。
// 宣告用來儲存先前對話的陣列
let conversation = [];
conversation.push({
role: "system",
content: "我是一個友善的生成式預訓練模型",
});
let previousMessages = await message.channel.messages.fetch({ limit: 10 });
previousMessages.reverse();至於為何會需要將 fetch 到的訊息進行反轉,是因為 Discord API 預設擷取訊息是從最新的訊息開始,而我們需要將擷取到的訊息進行排序,才能讓整體的對話邏輯更加合理。
然後將 fetch 到的訊息進行迭代處理,將訊息資料結構化,並且一一儲存到 conversation 陣列中。
這裡稍微解釋程式碼中的一些細節:
- 如果只判斷 msg.author.bot 會導致機器人忽略自己的訊息,所以要加上
msg.author.id !== client.user.id就是如果消息來自其他機器人(但非當前機器人自己),如果任何這些條件成立,則透過 return 跳過當前迭代,不將該消息加入 conversation 陣列中。 - 一樣判斷如果訊息是以 ! 開頭,就忽略不處理
- 由於 OpenAI 的 GPT 模型不允許 name 含有特殊字元,因此會透過正規化將使用者名稱中的空白字元替換成底線,並且移除特殊字元
- 如果訊息是來源是機器人本身,則將訊息的角色設定為 assistant,來使 GPT 模型的回覆更具有對話性
- 再判斷如果訊息是來源是使用者,則將訊息的角色設定為 user,讓 GPT 把訊息當作是使用者的訊息來回覆
previousMessages.forEach((msg) => {
if (msg.author.bot && msg.author.id !== client.user.id) return;
if (msg.content.startsWith(IGNORE_PREFIX)) return;
const discord_username = msg.author.username.replace(/\s+/g, "_").replace(/[^\w\s]/gi, "");
if (msg.author.id === client.user.id) {
conversation.push({
name: discord_username,
role: "assistant",
content: msg.content,
});
return;
}
conversation.push({
// 將使用者的訊息回傳給 OpenAI GPT 模型,並且將訊息資料結構化,並且儲存到 conversation 陣列中
name: discord_username,
role: "user",
content: msg.content,
});
});然後就可以將原本 message 內的寫死的訊息從改成 conversation 陣列,並且將 conversation 陣列送到 OpenAI GPT 模型中,讓 GPT 模型能夠記住上下文。
const response = await openai.chat.completions
.create({
model: "gpt-3.5-turbo-1106",
messages: conversation,
})
.catch((error) => {
console.log("OpenAI 模型發生錯誤:( :\n", error);
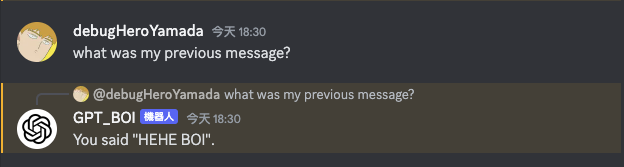
});這樣就成功從原本只會處理單一訊息到能讀取對話歷史紀錄,並且能夠記住上下文的機器人了。
# Discord 訊息字數限制解決辦法
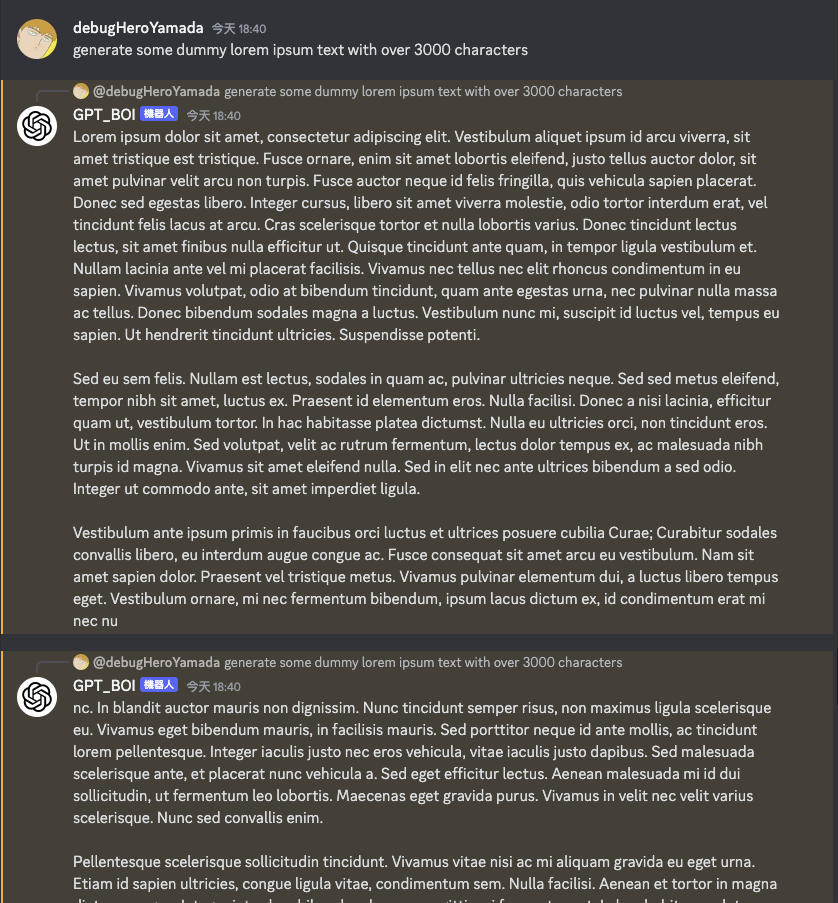
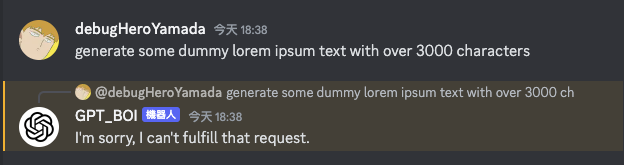
由於 Discord 單個訊息最長只能有 2000 個字元,因此可以將訊息切割成多個訊息,並且分批發送。
原本若無額外針對長文本進行切割處理的話,會導致機器人無法回覆訊息:
所以這裡可以先:
- 提取 GPT 回覆訊息
- 設定字元分割大小,這邊就設定為 Discord 訊息字數限制的 2000 個字元
- 使用 for 循環來分割長消息。循環從 0 開始,每次增加 chunksSize(2000字元),直到遍歷完整個
discord_responseMessage字符串。 - 使用 await 確保分割後訊息能依序回覆
// message.reply(response.choices[0].message.content); // GPT 機器人回覆的訊息
discord_responseMessage = response.choices[0].message.content;
const chunksSize = 2000;
for (let i = 0; i < discord_responseMessage.length; i += chunksSize) {
const chunk = discord_responseMessage.substring(i, i + chunksSize);
await message.reply(chunk); // 用 await 確保訊息能 依序回覆
}就能夠成功看到我們的 GPT 能夠回覆長文本訊息啦!