第一次打開 K9s,看到一堆服務和不同的 IP,心裡只有一個問號——這些 IP 是什麼?為什麼跟自己架 VPS 感覺完全不一樣?
這篇就是那次頓悟的記錄。
# K9s 是什麼?跟 EKS 有什麼關係?
先釐清一個常見的混淆:
- K9s — 終端機介面的管理工具,讓你不用背一堆
kubectl指令就能操作 K8s 叢集。它是「監視器」。 - EKS (Amazon Elastic Kubernetes Service) — AWS 託管的 Kubernetes 服務,提供底層的運算資源。它是「工廠」。
K9s 畫面上方的 Context 欄位通常長這樣:
arn:aws:eks:ap-northeast-1:xxxxxxxxxx:cluster/your-cluster這代表 K9s 目前連線到的是一個位在 AWS 東京區域的 EKS 叢集。
# 那些不同的 IP,其實是不同的電腦
這是最讓人驚訝的一刻。
K9s 的 NODE 欄位會顯示類似這樣的主機名稱:
ip-192-168-77-77.ap-northeast-1.compute.internal
ip-192-168-15-15.ap-northeast-1.compute.internal
ip-192-168-11-235.ap-northeast-1.compute.internal每一個不同的 IP,就是 AWS 上一台獨立的 EC2 Instance(虛擬機器)。
這就是 K8s 叢集的本質:把多台電腦合體成一個巨大的資源池,讓工程師不需要管「程式跑在哪台機器上」,只需要管「服務有沒有正常運行」。
# 跟自己架 VPS 有什麼不同?
| 特性 | 普通 VPS 部署 (Traditional) | EKS / K8s 部署 (Cloud Native) |
|---|---|---|
| 環境隔離 | 服務直接跑在 OS 上,容易發生 A 套件跟 B 套件衝突 | 每個服務都在獨立的 Container (Pod) 裡,互不干擾 |
| 掛掉怎麼辦 | 服務掛了要自己進去重啟 | 自我修復 (Self-healing):K8s 發現 Pod 掛了會自動秒速重啟 |
| 擴展性 | 使用者變多時,要手動再租一台 VPS 並手動同步程式 | 自動擴展 (Auto-scaling):壓力大時自動增加機器和服務數量 |
| 負載平衡 | 要自己設定 Nginx 反向代理,手動對應每個 Port | 內建 Service / Ingress:自動幫你分配流量到正確的 Pod |
傳統 VPS 最大的問題是單點故障(SPOF)。如果你把 20 個服務全塞在一台機器,硬碟壞了或網路斷了,全軍覆沒。
而 K8s 的設計理念是:不在乎某台電腦掛掉,因為服務會自動搬到別的電腦繼續跑。
# 技術底層:無縫切換是怎麼實現的?
這是最硬核的部分。K8s 靠三個核心組件實現自動感知與切換。
# 1. etcd — 叢集的唯一真理來源
etcd 是一個分散式 Key-Value 資料庫,記錄了整個叢集的所有狀態:
- 哪些節點(電腦)目前是活的
- 每個服務應該跑幾個副本
- Pod 目前分配在哪台機器上
每台電腦都會定時向 etcd 發送心跳(Heartbeat)。如果某台機器突然斷網或當機,心跳停了,etcd 就會標記它為 NotReady。
# 2. Controller Manager — 永遠不休息的監工
Controller Manager 不斷執行一個簡單但強大的死循環:
現在的狀態 ≠ 你要求的狀態? → 立刻修正實際場景:
- 你在設定檔宣告:「我要跑 1 個
freeswitch」 - 承載它的機器突然掛了,現在實際跑著 0 個
- Controller 發現
0 ≠ 1,立刻找一台健康的節點下令:「把freeswitch跑起來!」
這就是為什麼你可能在 K9s 上看到某個服務的 RESTARTS 高達上萬次——K8s 一直在幫你嘗試把它拉回來。
# 3. kubelet — 每台電腦上的特務
每台加入叢集的機器都跑著一個叫 kubelet 的程式。它負責:
- 監控這台機器的 CPU / RAM 狀況並回報
- 接收 Controller 的命令,把指定的 Container 跑起來
- 執行 Liveness / Readiness Probe(存活探針)
存活探針每隔幾秒就問服務:「你還活著嗎?準備好接流量了嗎?」如果服務沒回應,kubelet 會直接判定它死亡並重啟,同時通知上層切斷導向它的流量。
# 4. Service & Kube-proxy — 穩定的傳送門
這是最神奇的地方:Pod 換台機器跑,IP 就會變,但外面的使用者怎麼還連得到?
答案是 Service。K8s 提供一個固定的 Service IP 作為入口。不管底層的 Pod 怎麼漂移、換到哪台節點,Service 都會自動把流量導向目前健康的 Pod。
整個無縫切換流程大概是這樣:
Node A 斷電
→ etcd 偵測到心跳消失,標記 Node A 為 NotReady
→ Controller 發現服務數量不足,呼叫 Scheduler 找空位
→ Node B 的 kubelet 接到指令,拉起服務
→ Service 更新路由,流量導向 Node B這一切通常在幾秒內自動完成。工程師還在睡覺,系統就已經自己修好了。
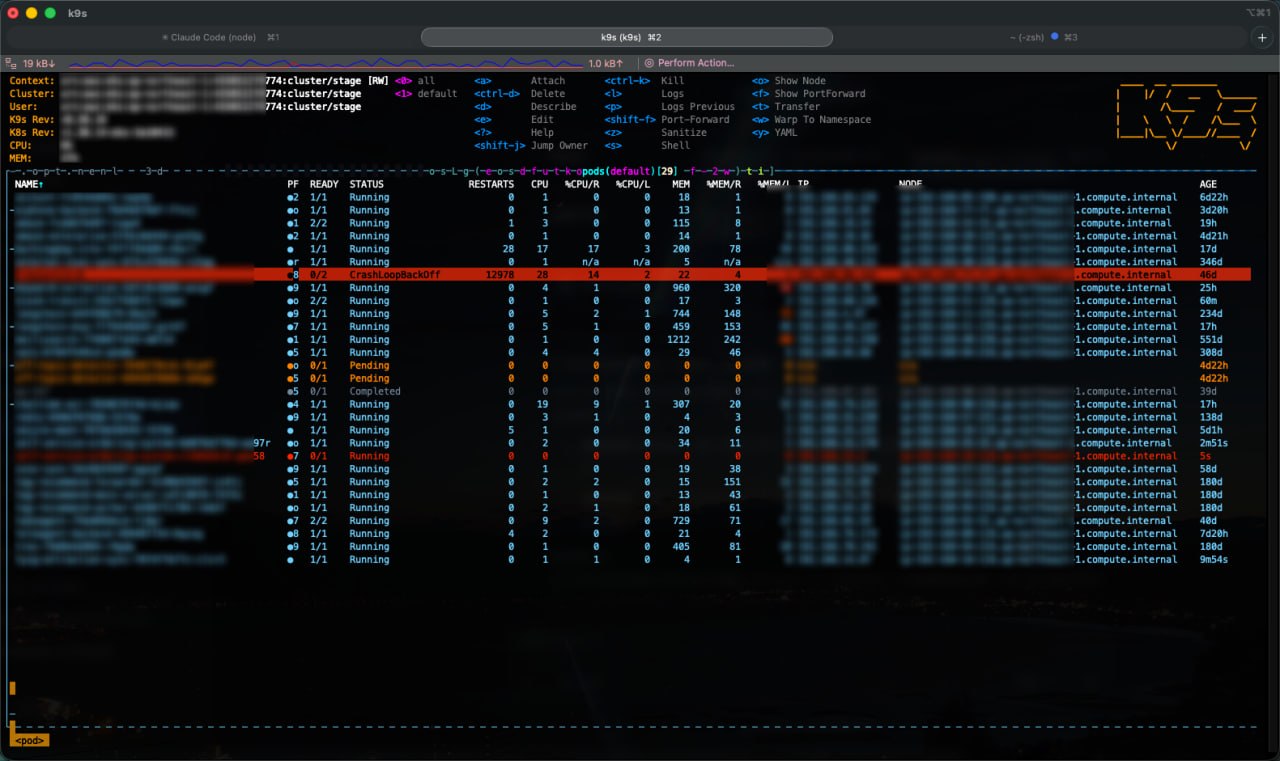
# 實戰畫面
這是一個真實的 K9s 畫面,可以看到:
- 紅色的
freeswitch-0狀態是CrashLoopBackOff,重啟次數高達 12,978 次,代表服務一直啟動失敗,K8s 不斷嘗試幫它拉起來 - 橘色的
Pending服務正在等待節點資源被分配 - 右側的
NODE欄位可以清楚看到不同服務跑在不同的 IP(不同的電腦)上
# K9s 實用快捷鍵
| 快捷鍵 | 功能 |
|---|---|
l |
查看 Pod 目前的即時 Logs |
p |
查看 Pod 上次崩潰前的 Logs(診斷 CrashLoopBackOff 必用) |
d |
Describe Pod,看詳細設定與事件紀錄 |
:nodes |
切換到節點視角,看所有機器的資源負載 |
f |
在 Log 畫面暫停滾動 |
s |
將 Log 存成本地檔案 |
CrashLoopBackOff 診斷建議: 先按
p看上一次崩潰的 log,而不是l看即時 log。服務一直重啟的情況下,即時 log 通常只有啟動訊息,真正的錯誤在「死前的最後遺言」。
# 總結
K8s 的核心理念是宣告式(Declarative)管理:
你告訴 K8s「我要什麼狀態」,K8s 自己想辦法維持這個狀態。
它不在乎程式跑在哪台電腦,只在乎你定義的目標有沒有被滿足。這種設計讓系統具備了自我修復的能力,也是現代雲端架構能夠「高可用」的根本原因。
下次看到 K9s 上一堆不同的 IP,你就知道那是一群正在默默支撐系統的幕後英雄了。