
# 前言
由 openAI 開發的三大模型:
- WhisperAPI:聲音
- DALL-E:圖像
- GPT:文字
其中這專案使用到的是 WhisperAPI,一個能達到準確率極高的 speech to text , automatic speech recognition 的 Model。
# Google Colab 或 Docker
此專案有兩種運行方式,一種是使用 Google Colab,另一種是使用 Docker
# Docker
- 可以用自己的電腦資源進行運算,不用擔心被 Google Colab 限制資源。
- 電腦本身配置要求較高、Docker 吃很多 RAM。
# Google Colab
- 電腦若配置較低,可以直接用 Google Colab 的資源進行運算。
- 畢竟是免費的,會限制資源,所以可能會有延遲的問題。
而我個人是使用 Docker,因為小弟本身電腦配置還可以,且流程簡單許多,而且會比較沒有延遲的問題。
# 前置作業
有些軟體 Mac 及 Linux 可能不支援,所以此專案是在 Windows 11 上運行,所以以下的步驟都是在 Windows 11 上的操作。
# Clone 專案
- 將專案 Clone 至自己本機端
git clone https://github.com/SociallyIneptWeeb/LanguageLeapAI - 下載此專案需要的套件
pip install -r requirements.txt
# 下載必要的軟體
- Docker Desktop:下載必要的 Docker Image 用
- Voicemeeter Banana:為了區分應用程序、系統音頻和 python 之間的正確路由和分離音頻
- Virtual Audio Cable:由於 Voicemeeter Banana 提供的虛擬電纜數量不夠,需額外安裝一條虛擬 Cable。
- 下載並安裝 VB-CABLE 驅動程序,解壓所有文件,以管理員模式運行安裝程序。安裝完畢後重新啟動。完成後,即可開始用 Voicemeeter Banana 設置音頻路由
# Audio Routing
此步驟要達到的目的:
- 配置系統以使用 Voicemeeter Banana 作為其主要的 I/O 音頻設備
- 將系統音頻和應用程序音頻導向自己的揚聲器/耳機
- 將應用程序的音頻與系統的其他部分隔離,讓 Whisper 進行 ASR(Automatic Speech Recognition)語音辨識技術。
此步驟是為了解決 Whisper API 會嘗試 transcribe 所有音源(System Audio,Apps Audio,TTS Audio) , 所以要讓 Python 指去抓取 Virtual Cable 的 Auxiliary Cable
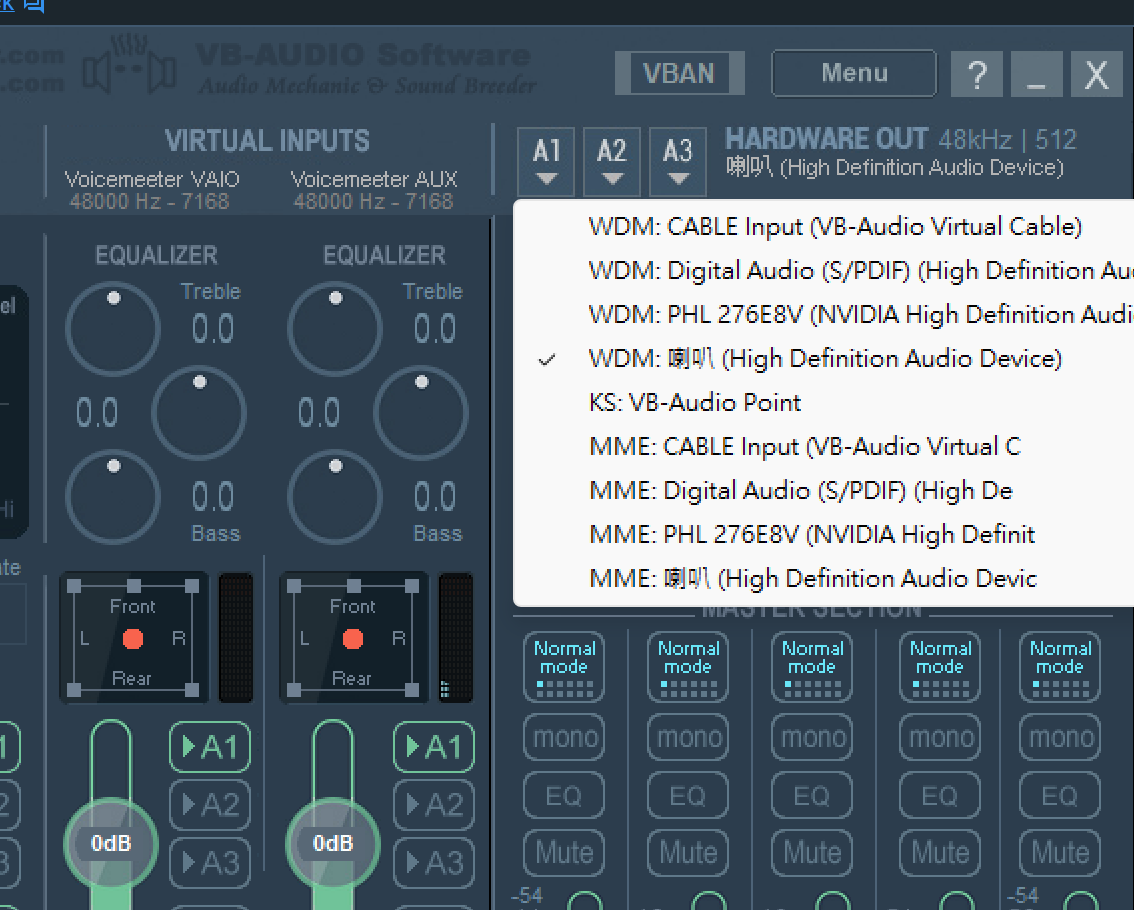
下載完 Voicemeeter Banana 後,打開 Voicemeeter Banana,並將其設置為系統的主要音頻設備,
點擊 A1並將 WDM 選項設置為你原本的音頻輸出設備
# Docker 啟動本機服務器
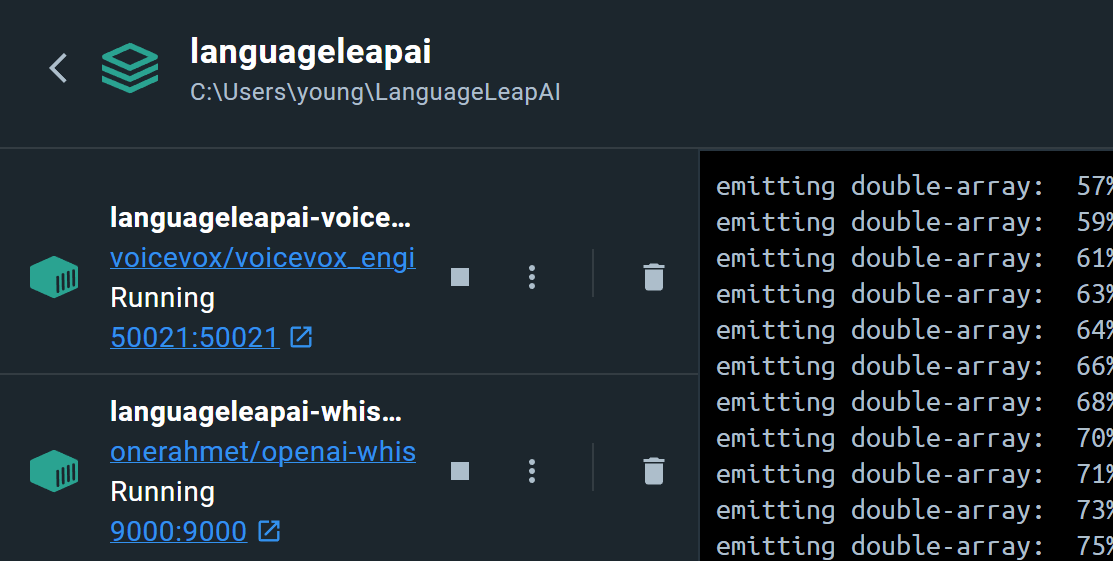
去專案目錄執行 docker-compose up -d,就會看到 Docker 開始下載 Image,並且啟動 Container,
PS C:\Users\young\LanguageLeapAI> docker-compose up -d
[+] Running 3/3
- Network languageleapai_default Created 0.6s
- Container languageleapai-whisper-1 Started 2.3s
- Container languageleapai-voicevox-1 Starte... 2.3s點擊 50021 網址後,去到 http://localhost:50021/docs,就可以看到 voicevox 回傳介面
往下拉找到 GET /speaker

點擊 GET 後 execute 後,就會看到 voicevox 的個個聲優名稱及 ID
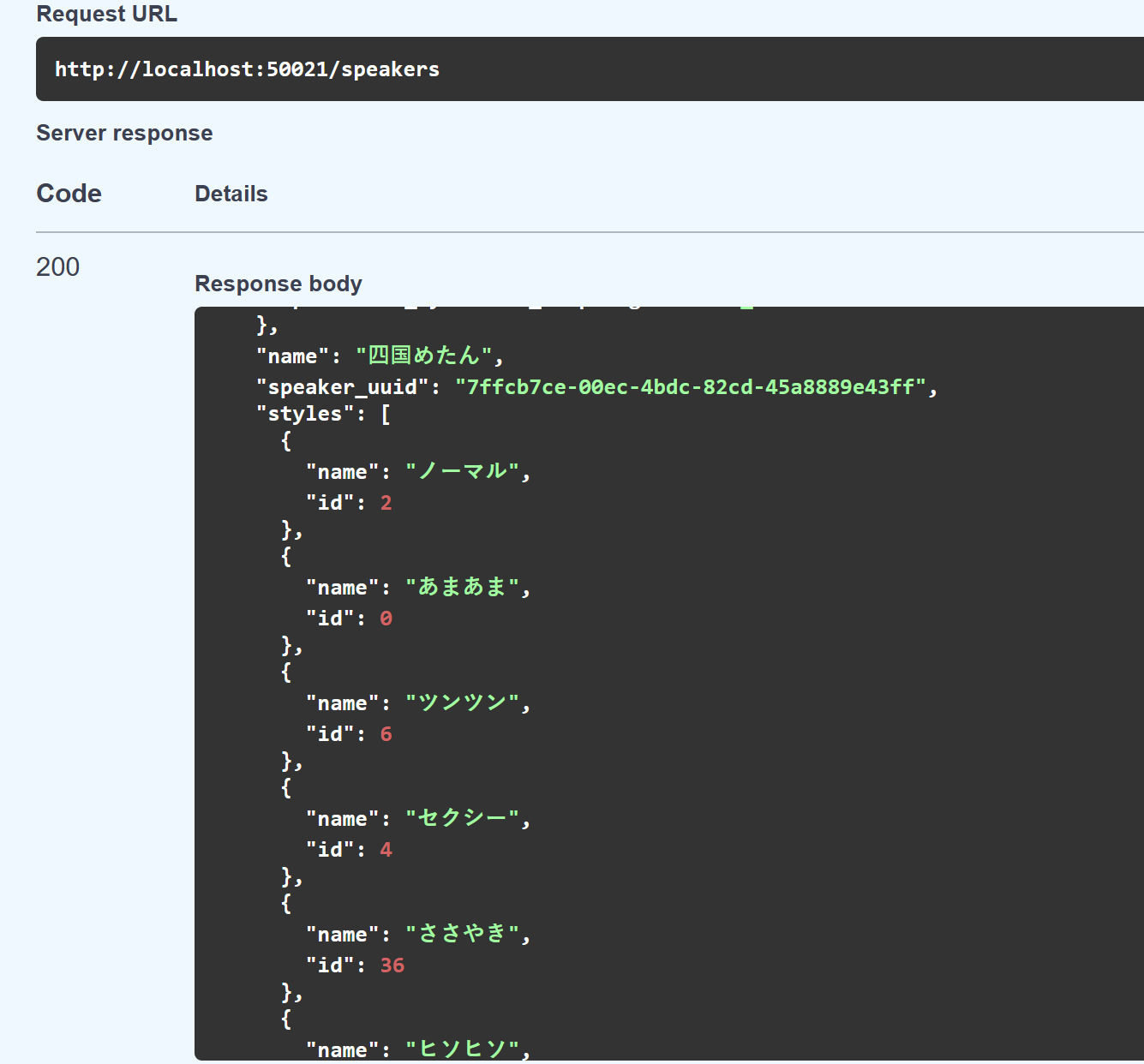
看不懂日文沒關係可以直接去 VoiceVox 官網,找自己喜歡的聲音試聽,然後直接複製名稱, 回去 Response body 的畫面按 Ctrl+F 找到對應 ID 即可。
# 編輯 .env 檔
- 拷貝 .env.example 檔案,並將檔名改為 .env
cp .env.sample .env - 用 Google 翻譯或 DeepL API,DeepL 翻譯會比較自然, API 每月只提供 500,000 字元的免費翻譯。要用 DeepL 就設置 True,Google 翻譯就 False
- 執行
python src/modules/get_audio_device_ids.py來抓取自己各個音頻設備的 ID (每次重新開機都會變)。 - 將
MICROPHONE_ID、VOICEMEETER_INPUT_ID、CABLE_INPUT_ID....設定至剛剛抓取出來的對應 ID。
# .env
....
# True 的話就是用 DeepL API,False 的話就是用 Google 翻譯
USE_DEEPL=True
### DEEPL AUTHENTICATION KEY ###
# Sign up for the free plan at https://www.deepl.com/pro-api?cta=header-pro-api/
# Then go to https://www.deepl.com/account/summary , scroll down and copy your auth key
# Only required if USE_DEEPL is set to True
DEEPL_AUTH_KEY=
### 按下此鍵開始說話 ###
# Key to hold down when speaking, e.g v, e
MIC_RECORD_KEY=f
......
### 音頻設備 ID 設定 ###
# 執行 src/modules/get_audio_device_ids.py 來取得自己的音頻設備 ID
# 麥克風 ID
MICROPHONE_ID=
# VoiceMeeter Input (VB-Audio VoiceMeeter VAIO)
# Plays Text-to-Speech audio into your speakers/headphones for you to hear
VOICEMEETER_INPUT_ID=
# CABLE Input (VB-Audio Virtual Cable)
CABLE_INPUT_ID=
# VoiceMeeter Aux Output (VB-Audio VoiceMeeter AUX VAIO)
# Where your application audio (voice-chat) will play from
AUX_OUTPUT_ID=
### VOICEVOX SETTINGS ###
# 輸出聲優的 ID
VOICE_ID=15
.......# 相關連結
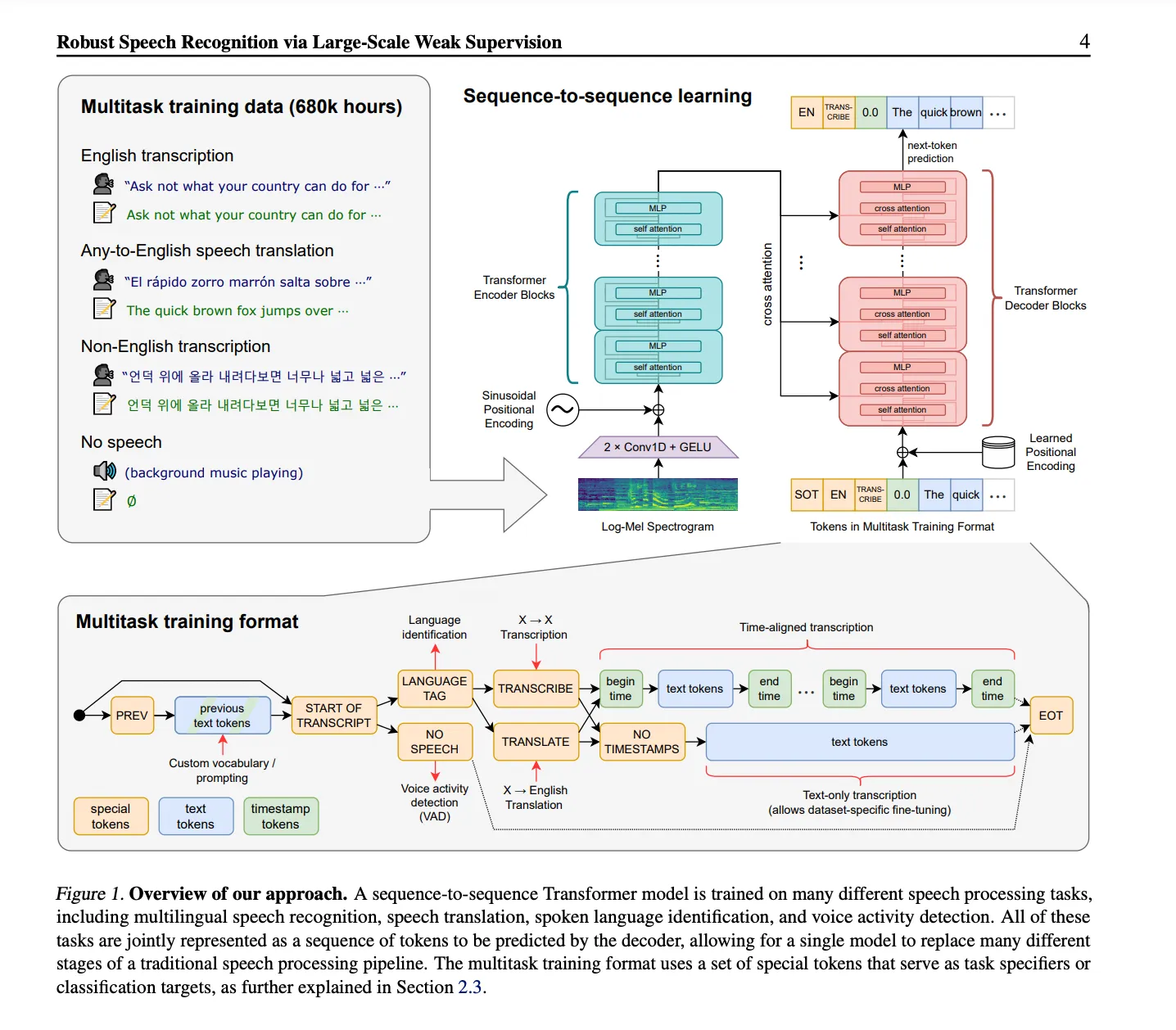
- Whisper API:由 OpenAI 開發的通用語音識別模型(
Transformer sequence-to-sequence model),可進行多語言語音識別、語音翻譯、口語識別和語音活動檢測。 - DeepL Translator:由 DeepL 開發的神經網絡翻譯工具,可以進行多語言翻譯,比 Google 翻譯更自然。
- Voicevox: 日本免費的深度學習語音合成器,非常佛心。